A “data lake” is a storage repository, usually in Hadoop, that holds a vast amount of raw data in its native format until it is needed. It’s a great place for investigating, exploring, experimenting, and refining data, in addition to archiving data. Some characteristics of a data lake include:
- A place to store unlimited amounts of data in any format inexpensively
- Allows collection of data that you may or may not use later: “just in case”
- A way to describe any large data pool in which the schema and data requirements are not defined until the data is queried: “just in time” or “schema on read”
- Complements an Enterprise Data Warehouse (EDW) and can be seen as a data source for the EDW – capturing all data but only passing relevant data to the EDW
- Frees up expensive EDW resources (storage and processing), especially for data refinement
- Allows for data exploration to be performed without waiting for the EDW team to model and load the data
- Some processing in better done on Hadoop than ETL tools like SSIS
- Also called bit bucket, staging area, landing zone or enterprise data hub (Cloudera)
To use some pictures to show the benefit of a data lake, here is the traditional approach for a data warehouse environment:
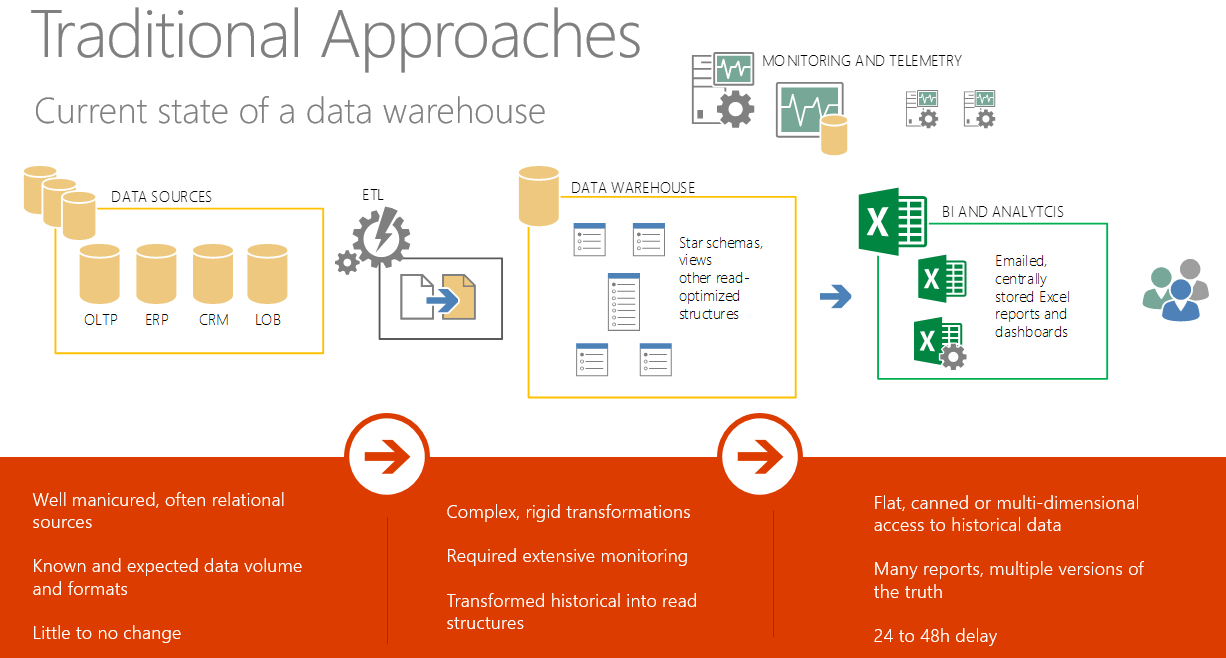
But as we introduce larger data volumes into this environment along with non-relational data, we run into problems:
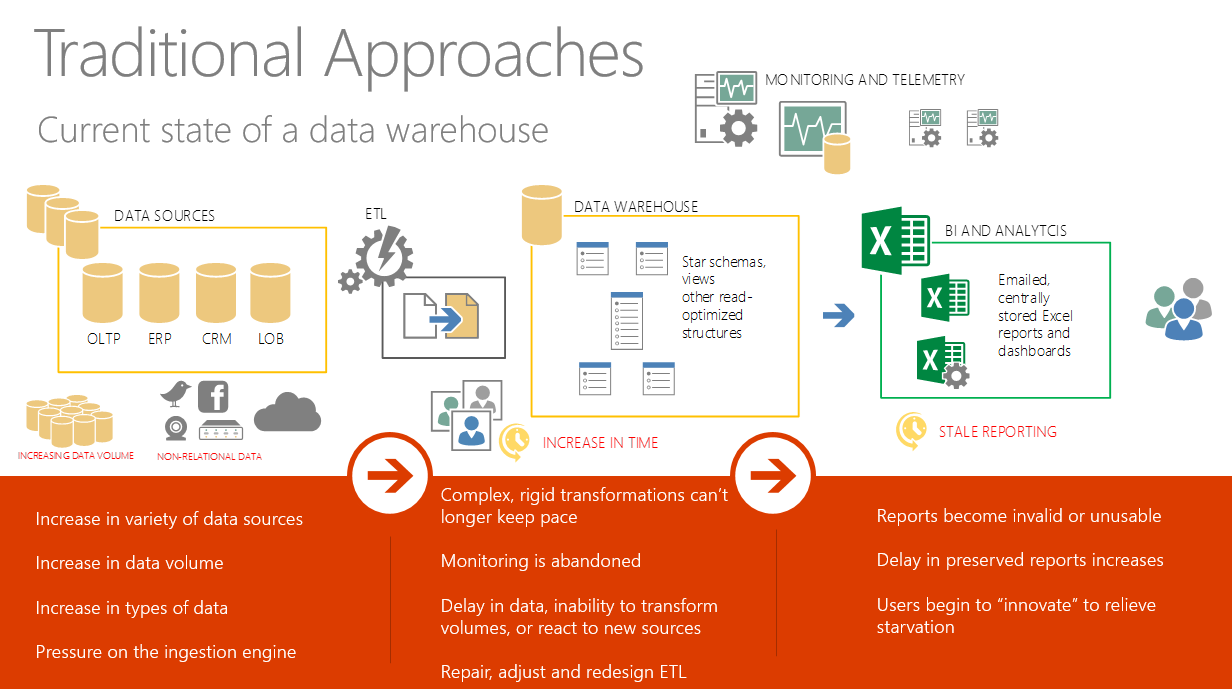
The impact if we keep the current architecture:
- Drop useful data by introducing ETL “bias”
- Potentially insightful data is lost
- Create latency as volumes increase and sources change
- Duplicate data through staging environments to support ETL
- Expensive “reactive” hardware to support processing scale requirements
So we take a new approach, where the non-relational data is copied to a data lake and refined, and then copied to the data warehouse. Meanwhile, much of the relational data can keep being fed directly to the data warehouse using the current ETL, bypassing the data lake:

By changing the architecture for the analyst’s needs, we get the following benefits:
- Entire “universe” of data is captured and maintained
- Mining of data via transformation on read leaves all data in place
- Refineries leverage the power of the cloud and traditional technologies
- Integration with traditional data warehousing methodologies
- Scale can be pushed to cloud for more horsepower
- Orchestration of data is a reality (less rigid, more flexible, operational)
- Democratization of predictive analytics, data sets, services and reports
Note there are technologies, such as PolyBase, that allow end-users to query data in a data lake using regular SQL, so they are not required to learn any Hadoop-related technologies. In fact PolyBase allows the end-user to use SQL, or any reporting tool that uses SQL, to join data in a relational database with data in a Hadoop cluster.
More info:
Analysts Warn of Data Lake ‘Fallacy’ in Big Data Analytics
Make Sure Your Data Lake is Both Just-in-Case and Just-in-Time
Top Five Differences between Data Lakes and Data Warehouses
Hadoop vs Data Warehouse: Apples & Oranges?
Martin Rennhackkamp: Data Lake, Data Lake vs Data Warehouse, Building a Data Lake, Revolt against the Data Lake as Staging Area